
One of the biggest challenges in building a Network Functions Virtualisation (NFV) platform is reducing OPEX costs and bringing flexibility to the platform. Most vendors offer monitoring tools, however many tools don’t have the visibility to detect issues that are taking place within other components, requiring the use of multiple systems, increasing cost and reducing platform flexibility.
The Challenge
Platform agility is only possible if there is complete operational visibility across following components in NFV stack:
- Virtualized Network Functions (VNF)
- Virtualized Infrastructure Manager (VIM) where VNF workloads are deployed as either VMs/Containers
- Hardware/Infrastructure layer – Racks, Bare metal nodes
- Network Layer – Switches, Routers, SDNs
Most of the vendors offer different suites of monitoring tools in each component in order to ensure operational and production readiness of the layer that they are operating in. For instance, each VNF vendor rolls out a Virtual Network Functions Manager (VNFM) that handles life cycle events e.g. self-remediation of a service in VNF should it encounter a problem. However, this VNF-specific monitoring tool doesn’t have visibility of the issues that are occurring in any other components. Problem diagnosis requires an operator to interrogate multiple systems. This means multiple UI’s, multiple monitoring models and multiple views and / or reports.
The Aptira Solution
A centralised Service and Platform Assurance system is required to integrate with multiple heterogenous components. This solves the lack of complete visibility of the whole Network Functions Virtualisation platform across different Network Functions Virtualisation Infrastructure (NFVi) Points of Presence (PoPs). Implementing such a centralised system requires identifying all the failure domains in platform, their critical data points and mechanism to extract these data points.
So, key responsibilities of the system include:
- A data collection mechanism to collect data points such as performance metrics, usage
- A policy framework that defines a set of policies to correlate the data collected and perform corrective actions by detecting anomalies
- A single dashboard view that gives the information of all KPIs in the system such as Alarms, Capacity, Impacted services/components, Congestion
A representation of such a system is shown below:
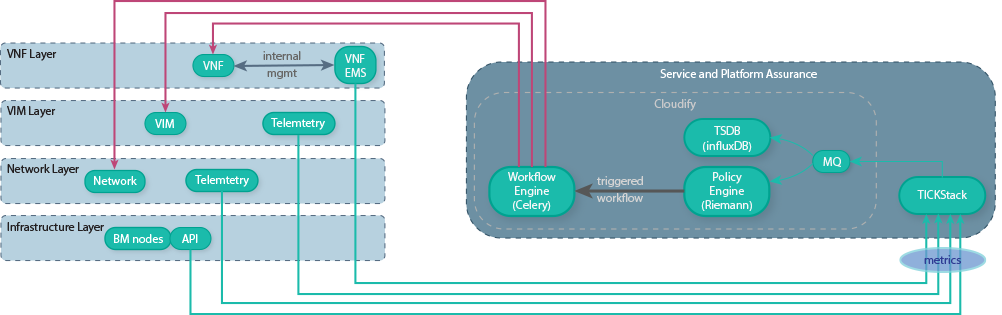
Aptira solved this for a large Telco by developing a framework using Open Source tools – TICK Stack and Cloudify. TICK stack was selected due to its wide community support and the stack’s existing integrations with 3rd party software components. Cloudify was selected because of its ability to handle CLAMP policies at scale across NFV domains.
TICK Stack uses Telegraf as its data collection component that uses a wide range of plugins to collect different set of data from multiple sources. Aptira used REST plugins to fetch the data from components such as VNFM, OpenStack, Kubernetes endpoints and used SNMP plugins from legacy VNFs. Once data is collected, they are then stored in InfluxDB database for further analysis.
TICK Stack uses the Kapacitor component for defining event management policies. These policies correlate events/data collected and triggers a corrective action. Aptira designed and implemented policies that acted on data collected from OpenStack endpoints and the VNF telemetry data to detect anomalies and triggers a remediation plan. For example, detecting that a VNF is unhealthy (e.g. due to high CPU load/throughput) and triggering a remediation process (e.g. Auto-Scale to distribute high-load across more instances of the VNF).
Since a VNF is modelled and orchestrated by Cloudify NFVO, Kapacitor policies interacts with Cloudify to perform a corrective action at a domain level, such as rerouting all the traffic being sent to the affected VNF to another VNF, and thereby applying a close loop control policy.
The Result
To have a complete visibility of the platform and the services that are running on them, it is important to have a subsystem integrated in Network Functions Virtualisation platform that not only ensures the uptime of the components, but also provides enough information to the Operations team to identify anomaly patterns and provide a quick feedback to the teams concerned.
These Open Source tools have enabled us to provide the required visibility into their NFV platform, reducing the customer’s OPEX costs and increasing flexibility of their platform.






